




Discover more from Artificial Ignorance
A stroll through Google's Model Garden
What generative AI capabilities does Google offer to developers?


The last few weeks have been absolutely chock-full of OpenAI news. I'm certainly guilty of playing my part. But if you spend time on AI Twitter (and I don’t really recommend you do that), you'd be forgiven for believing that OpenAI is the only API people use.

In reality, each of the major cloud platforms has its own AI offerings, many of them quite sophisticated. But because they're not as buzzy as OpenAI, and perhaps because they don't have a viral consumer product like ChatGPT, they're often overlooked. Or at least, they don’t come across my radar very often.
So in an effort to expand my own horizons, and hopefully yours as well, I want to take a look at the AI platforms from big tech companies - starting with Google.
I'll be primarily looking at what features and models are available, and drawing some rough comparisons with OpenAI. I won't be building any new projects with Google's models - though I hope to do that in the future. Nor will I be benchmarking any performance metrics.

But when it comes to LLMs, my impression is that GPT-4 is still the most sophisticated, followed by Claude, GPT-3.5, and then open-source models. If you've got experience building with Google's LLMs, let me know in the comments!
Deciphering GCP
Google's developer offerings can be found within Google Cloud Platform (GCP). Like other cloud platforms, GCP is a sprawling mess of services, quotas, roles, dashboards, billing, permissions, and docs.
Even within the category of AI, there's an inscrutably long list of products and services. I'm sure all of these different list items have millions of users at any given moment, but for someone just getting started, it's almost impossible to know what to use.
That's a recurring critique of cloud platforms as a whole - because they're designed for enterprise customers, there's so much friction just to finish a basic integration. And it's one reason why OpenAI has captured so much developer mindshare - getting ChatGPT up and running takes less than ten lines of code.
But based on all of its marketing, it seems like Google is putting its latest and greatest capabilities inside of Vertex AI, which is where we'll dig in.
The two sides of Vertex
According to Google, Vertex AI is "a single environment to search, discover, and interact with a wide variety of models." In practice, it's two different platforms: a Generative AI platform, and an ML platform.
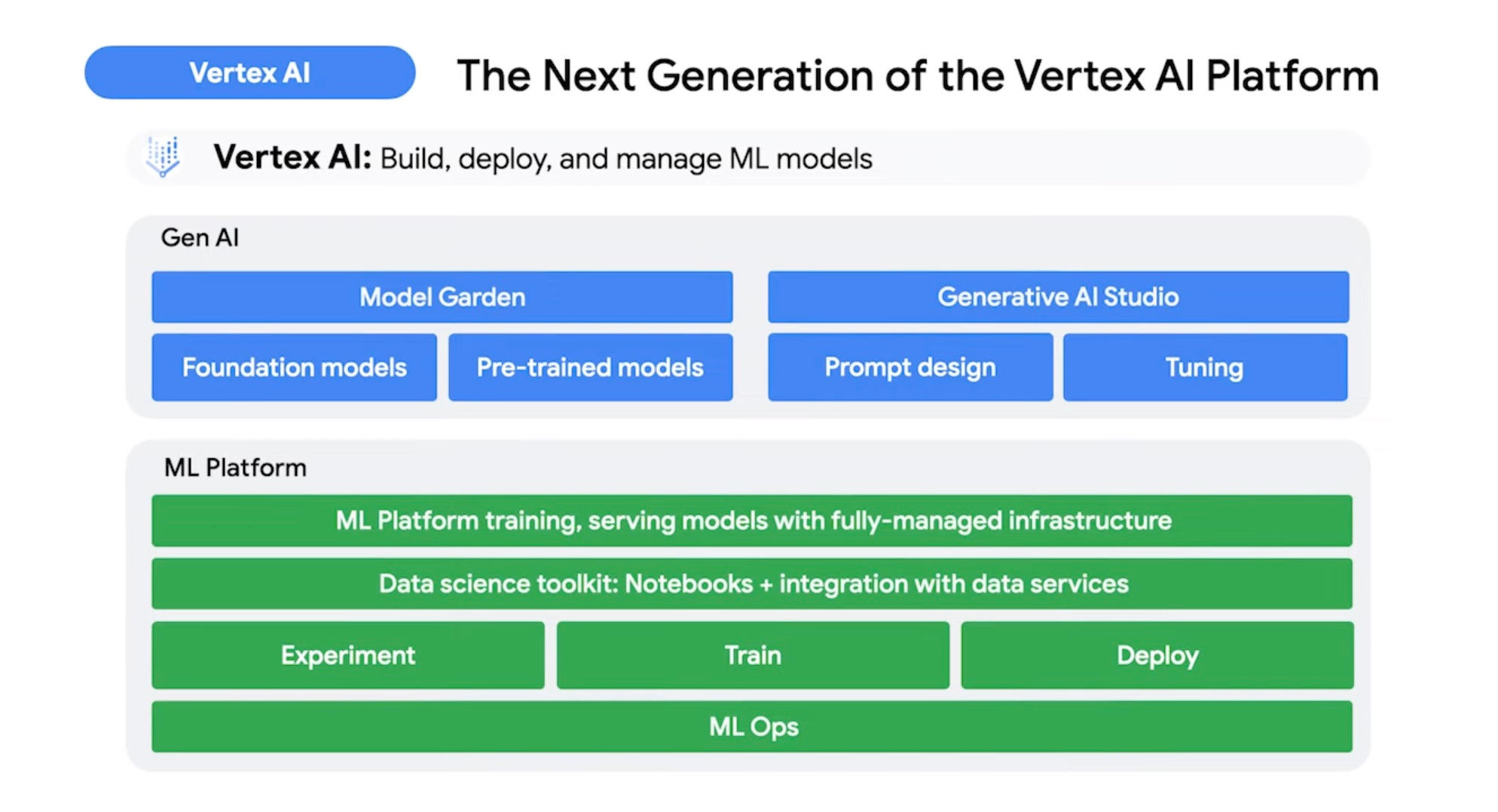
The generative AI side consists of the Model Garden and the Generative AI Studio - roughly equivalent to OpenAI's Playground. The ML platform, on the other hand, deals with all of the messiness required to actually deploy an ML model to production.
The rest of this deep dive is going to focus on the generative AI features, but I want to emphasize that ML Ops is still critical for making production-grade AI applications. It's easy to whip up a snazzy demo in a few hours using GPT-4. But it's a completely different ballgame to deploy LLM-powered features to thousands or millions of users - something AI Twitter often forgets.
If your use case isn’t completely covered by vanilla ChatGPT, you'll likely need a way to:
Fine-tune a custom model
Deploy one or more custom models
Collect user feedback and build an eval suite
Test different prompts and experiment with outputs
Yet despite having the most sophisticated LLM, OpenAI doesn't natively support fine-tuning and hosting custom models beyond GPT-3.5. GPT-4 fine-tuning is expected soon, but isn't widely available right now.
These ML Ops capabilities give Google a big advantage for companies looking to do more than use a single API. They’ve been building them for years, though the generative AI aspects have stolen the spotlight over the last year or so.
Thererfore, if you're looking for more specialized models that OpenAI doesn't yet offer, Google's Model Garden starts to look a lot more appealing.
The Model Garden
At first glance, the Model Garden seems very impressive.
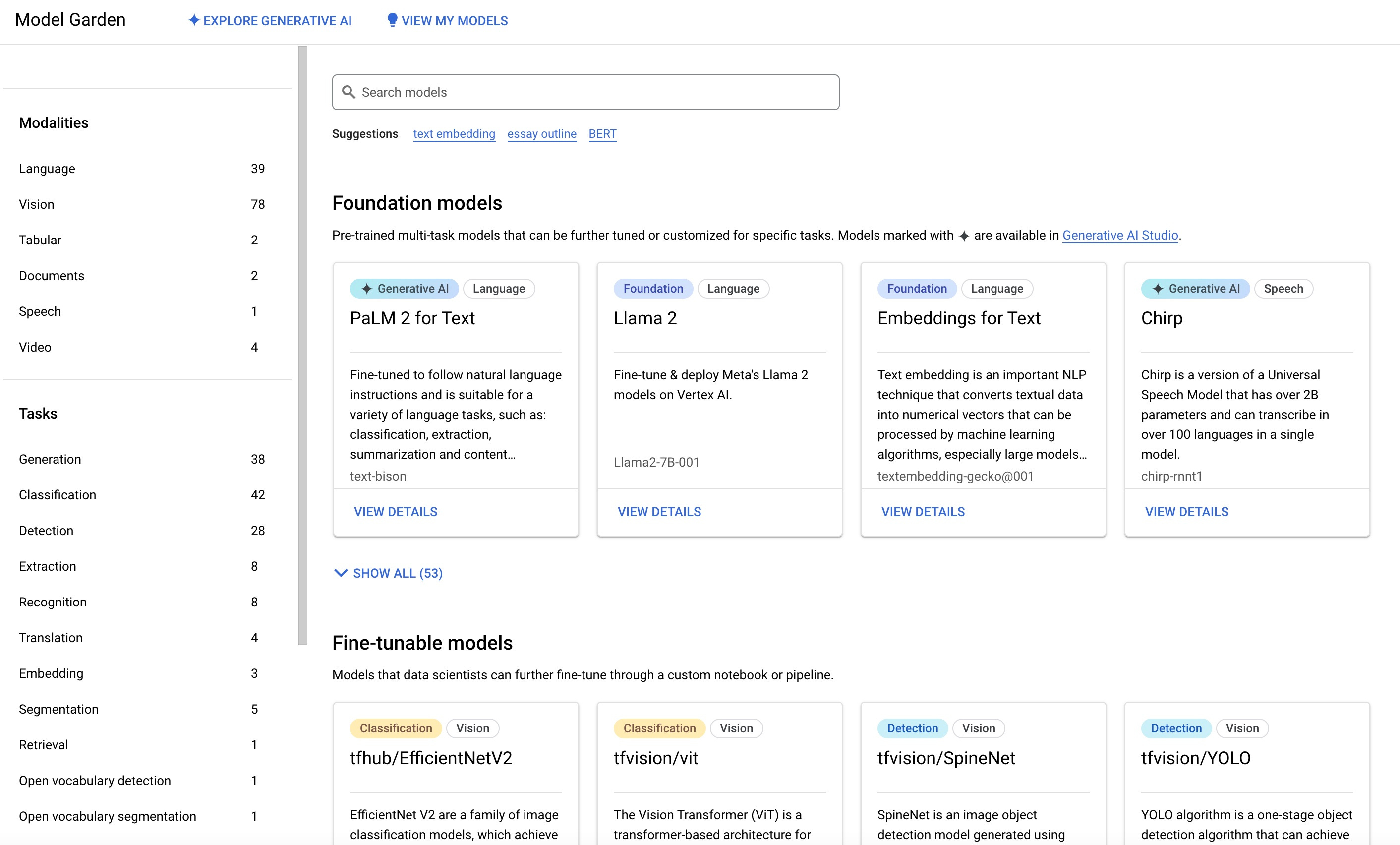
There are over 100 models available, and judging from the platform’s release notes, they add a handful of new ones every few months.
The models span a variety of modalities (text, image, audio, and video). The flagship Google models are available both as a pre-trained, consumable API, and within the Generative AI Studio. However, those represent a pretty small subset of the overall list (PaLM 2, Codey, Chirp, and Imagen).
There are also dozens of open-source options available to test and deploy. These include Llama 2 and Code Llama, but also Stable Diffusion (in multiple versions), ControlNet, CLIP, and Falcon.
What surprised me was the depth of task-oriented models that were present. This might be obvious to some, but I’ve been conditioned to see the world through OpenAI’s general-purpose assistant lens. With the Model Garden, I was reminded that machine learning was solving hundreds of narrow tasks before we entered a post-ChatGPT world. If you’re building with AI, I’d encourage you to browse the different models to get a sense of what’s possible if you move beyond the user/assistant response model.
Each model offers a “model card,” sort of a nutrition facts label for AIs. The cards include descriptions, use cases, and documentation - including example code and best practices.

Most models are available to either test out in Google Colab or deploy to Vertex’s ML platform. But the flagship foundation models are also available in the Generative AI Studio.
The Generative AI Studio
Even just one year ago, testing out a new LLM was a fairly involved process. Now, each month brings easier and easier ways to try out generative AI models - including the Generative AI Studio.
If you’ve used OpenAI’s Playground, the UI will be familiar.
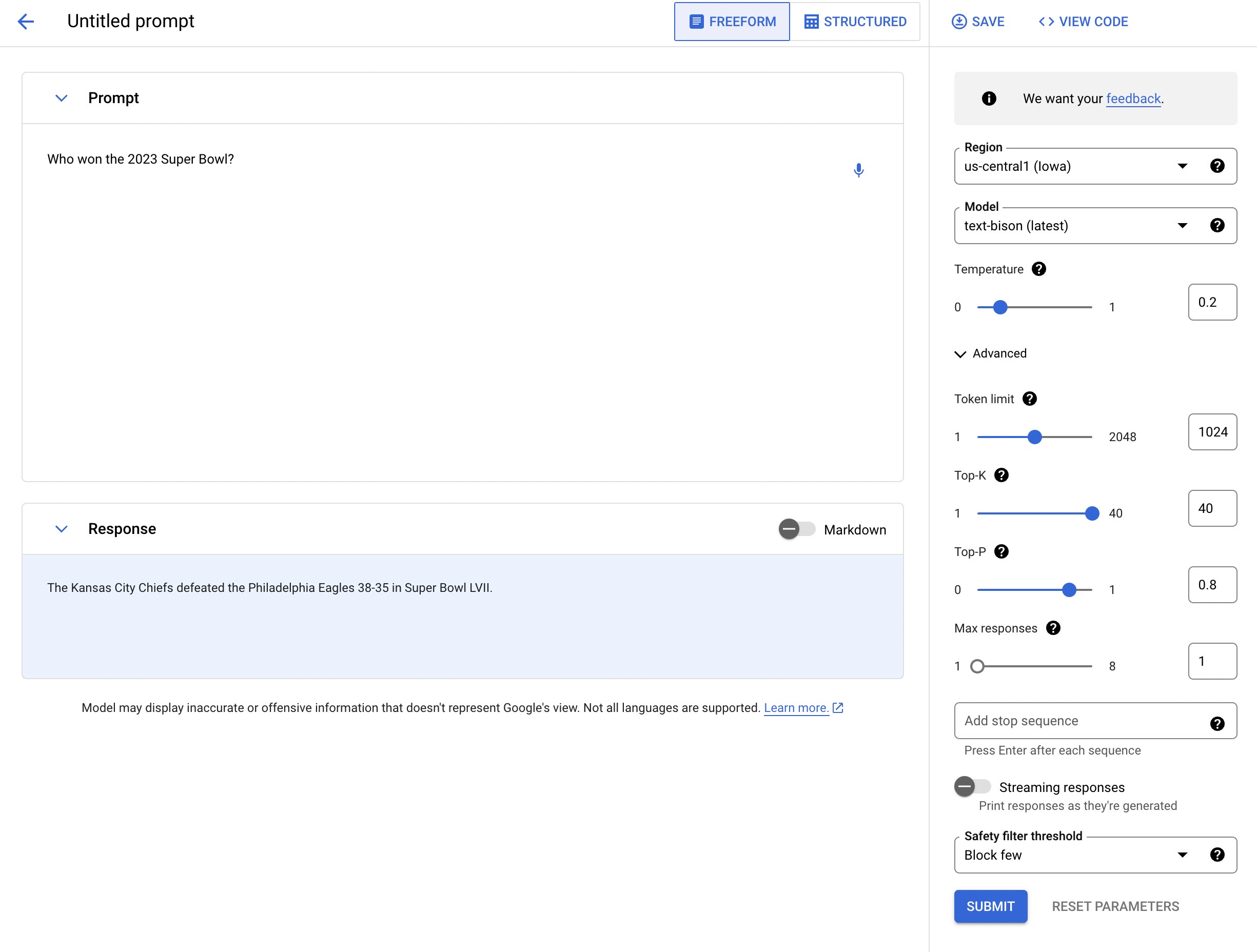
That said, there are a few additional features that the studio has:
A region switcher.
A max responses input - models can generate up to 8 responses at a time.
A streaming response toggle - by default, ChatGPT’s responses are streamed, meaning they appear one token at a time. Google’s responses, by default, aren’t displayed until the entire response has finished.
A safety filter threshold - the platform has an internal safety filter, and each response is evaluated on how likely it is to be harmful. This setting is able to adjust how sensitive the filter should be to harmful responses.
What’s also cool is the ability to fine-tune a model via their UI. The fine-tuning process supports both example-based tuning, as well as RLHF!
Like I mentioned at the top, I haven’t yet done any rigorous testing of these models to compare them with GPT-4. But in my very anecdotal experience, the latest models were not bad - roughly on par with the original ChatGPT. Plus, it clearly had a knowledge cutoff from sometime in the past year.

What to build with, then?
Ultimately many developers will face the question of what AI platform to build with. And the thoroughly unsatisfying answer is: "it depends."
From what I've seen (and I’ve built a few projects at this point), OpenAI is the fastest, most convenient system for prototyping a new project. Combined with the fact that it offers GPT-4 and GPT-4 Turbo, developing a proof of concept with OpenAI seems like the way to go.

But as your application gets more complex, the decision becomes a bit murkier. Do you need to host multiple models for different use cases? How are you collecting user feedback and structuring your evals? Using a cloud platform with all the bells and whistles can make managing infrastructure much easier at scale.
Decisions like the ones above are why many go with Microsoft Azure, as it provides exclusive access to OpenAI's models within a larger cloud platform offering. But that's a deep dive for another time.
Regardless, you'll want to keep tabs on how much vendor lock-in you're willing to put up with at any given moment. As AI platforms add more native capabilities, such as RAG or web browsing, the trend will be to bind users ever closer to the platform itself.









